



Google Canonical Page Algorithm Problems
The Problem The problem is that Google's indexing algorithms may inexplicably select incorrect "canonical pages" for a website, mistakenly selecting as "canonical" unrelated pages elsewhere on the site. This allows Google's algorithms to label completely original content as "duplicated" -- effectively making a mistake that no human would ever make -- and thus blocking original pages from appearing in Google search results. This can happen for 100s of pages on a website, blocking the entire site from appearing in Google search results, or if not the entire site, then its crucial pages (also known as "landing pages"). And, this can happen even though the blocked pages contain 100% original content, not duplicated anywhere else on the web, even including registered trademarks or copyrighted material, and otherwise following all of Google's published rules and guidelines. Probably, the new canonical page algorithm was implemented due to e-commerce abuses, for example 100s of e-commerce sites with pages having nearly identical content. Google has attempted to address this in the past, but -- as might be expected in any measure/counter-measure situation -- the e-commerce sites got better at subtly changing their pages so that Google's algorithms would see them as different. Basically, it's bot vs. bot warfare, and now Google has the upper hand again. Of course Google's focus on e-commerce completely ignores independent vendors providing infrastructure software solutions, which is the case for Signalogic. Below is a 16-mo performance history for signalogic.com, showing the time period when the canonical algorithm change "hit":
A: "Yes, changes, reorders, or narrows page content" Q: "How does this parameter affect page content?"
A: "Specifies" Q: "Which URLs with this parameter should Googlebot crawl?"
A: "Every URL" Below is a screenshot showing an example.
 3) Also related to 1), do not leave any short page names as active, or hanging around that Google can find, for example if you have old pages or are moving from http to https. Clean up any shorthand script parameters.
4) When you remove a page, make sure Google sees it as a "hard 404". It's not enough to return a soft 404. For page generation scripts, this might be an issue, depending on the programming of the script.
5) Any time Google mis-identifies your correct (target) canonical page, immediately attack the problem as follows:
3) Also related to 1), do not leave any short page names as active, or hanging around that Google can find, for example if you have old pages or are moving from http to https. Clean up any shorthand script parameters.
4) When you remove a page, make sure Google sees it as a "hard 404". It's not enough to return a soft 404. For page generation scripts, this might be an issue, depending on the programming of the script.
5) Any time Google mis-identifies your correct (target) canonical page, immediately attack the problem as follows:
- Remove the name Google chose wrongly. If you need to keep that page create a new name for it (long and descriptive, as noted above), and immediately re-index the new name. If you are using sitemaps, don't forget to remove the old name and add the new one and resubmit the sitemap. Basically, you want to leave no trail of the old name
- Attempt to re-index the old name, and verify that GSC rejects the request, seeing it now as a hard 404
- Re-index the target page
- If the old name was widely linked externally, use .htaccess rewrites to preserve it, but only do this once GSC shows the old name is no longer indexed. This can take some time, possibly several days
- They avoid extensive "dynamic content" to generate the page, which usually amounts to extensive reliance on Java script. Unfortunately Java script is increasingly seen as a security risk and an increasing number of users de-activate it
- They are widely used by small businesses and organizations that cannot afford dozens of Java script programmers and IT personnel to maintain highly complex web sites with 100s of pages of code (i.e. code vs. content)
2 For anyone wondering, the weekly click/impression oscillations are due to the nature of Signalogic's software products, which are B2B oriented (business-to-business). Typically business personnel are not searching for such products on weekends. Also by a ratio of more than 90%, they tend to use desktop search, not mobile.
Original Complaints
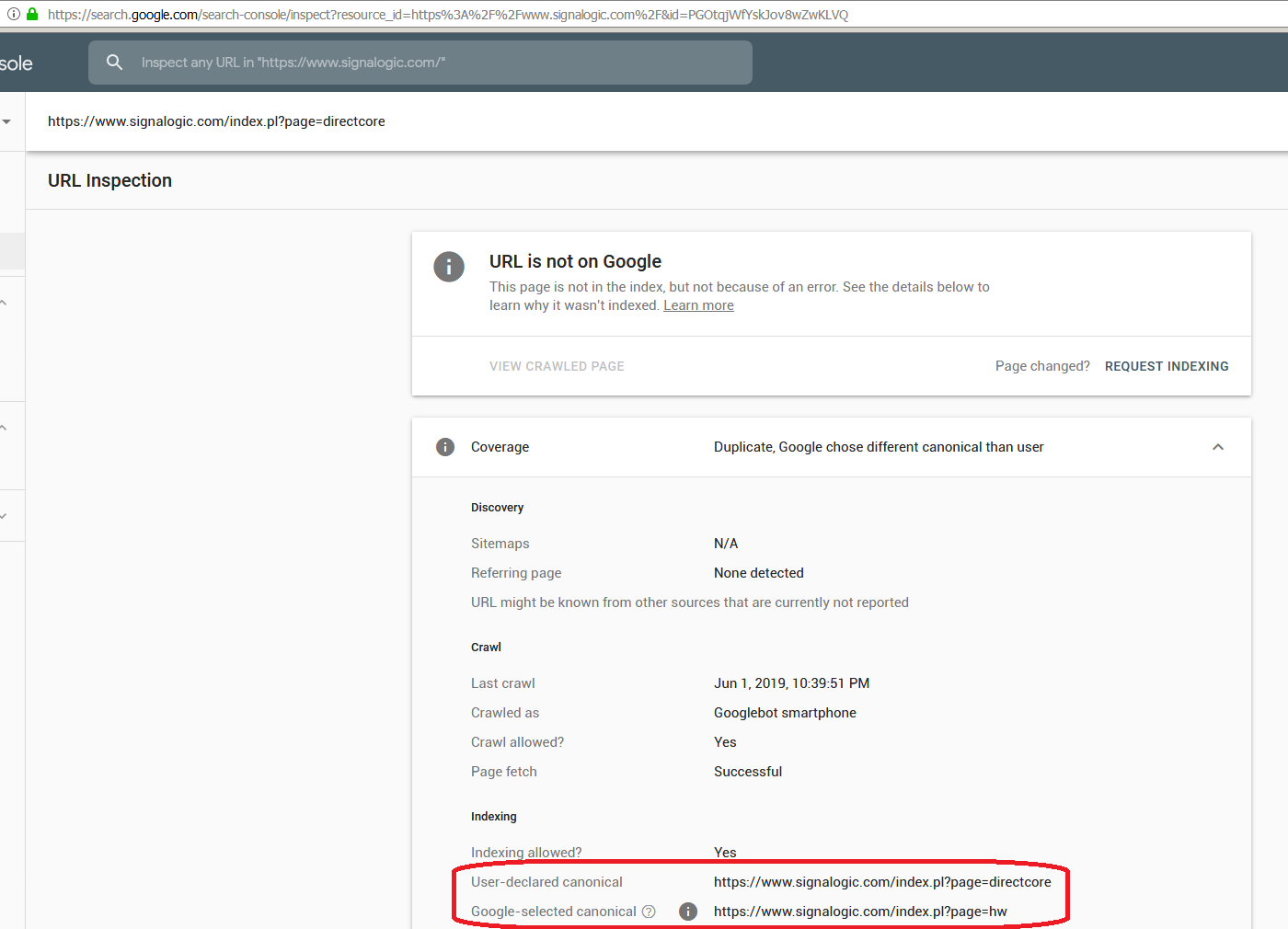
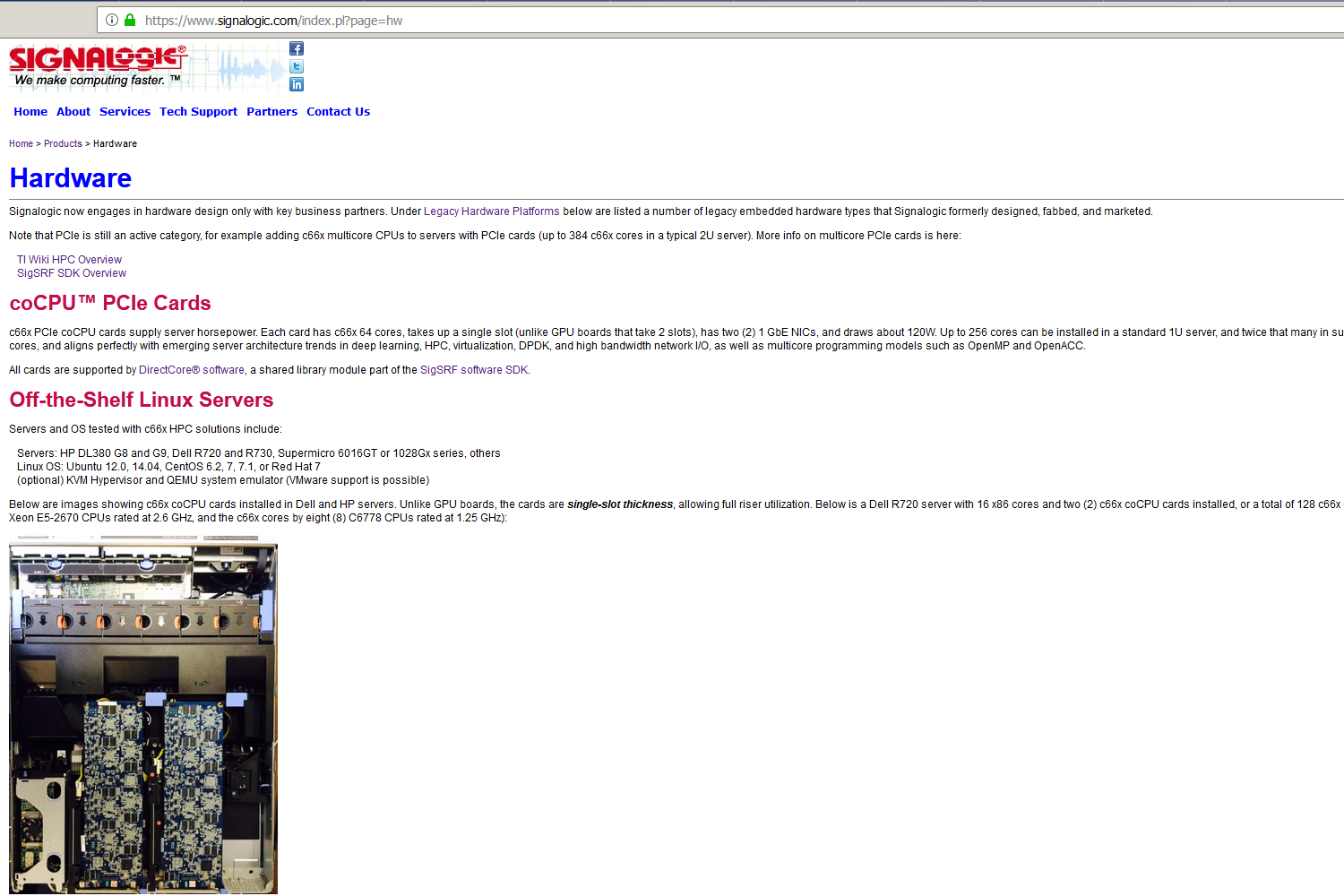
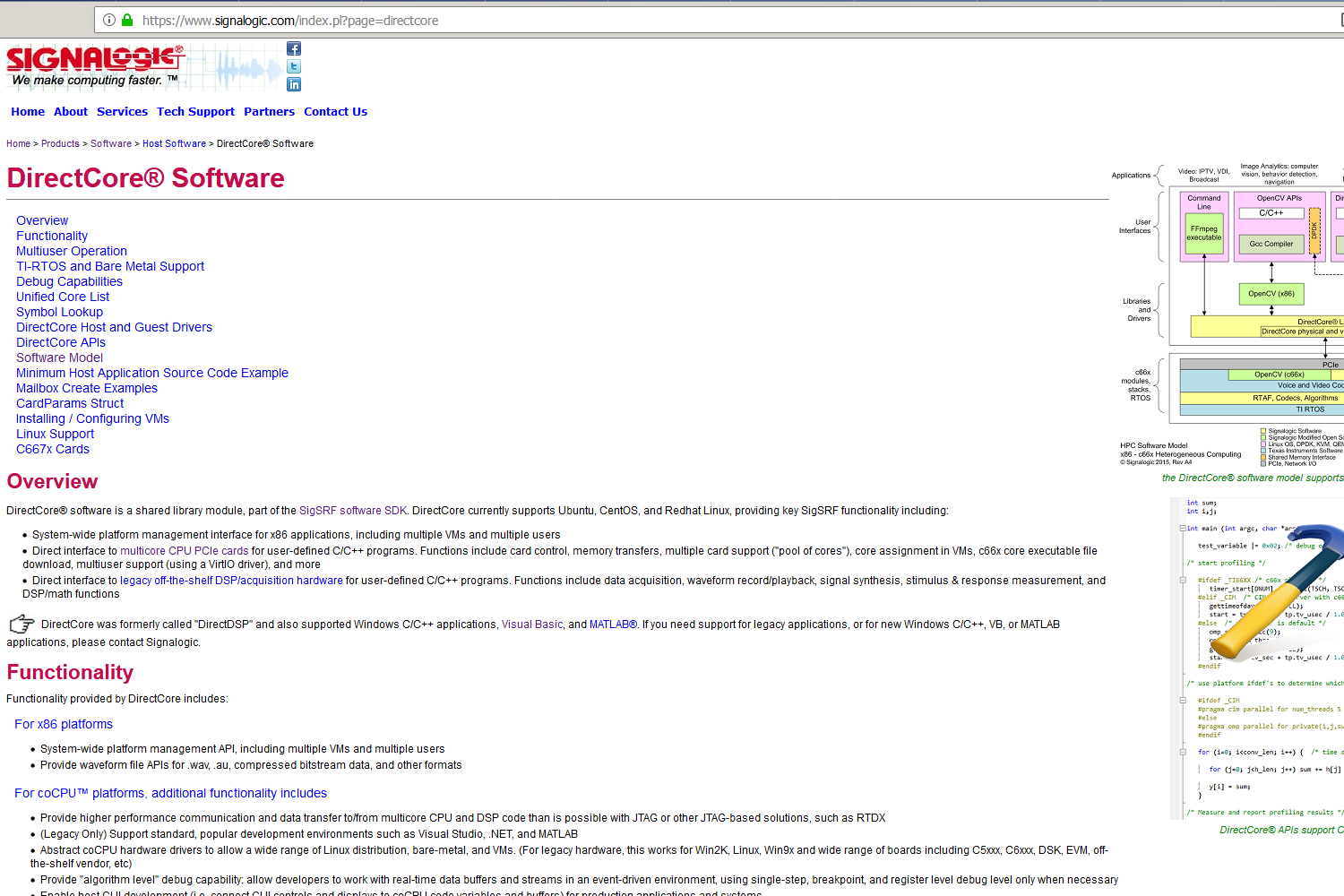
As a veteran-owned small business CEO, I have written this page to document a non-obvious, but crucial problem with Google Search. Google uses a "Canonical Page" algorithm to identify duplicate pages within a website and select one for indexing in Google Search. At best, this algorithm is buggy and does not function correctly. At worst, Google intentionally wrote this algorithm to deliberately disadvantage small business. Below is a "Google Search Console" screenshot showing the Canonical Page algorithm selecting a random, unrelated page on my company's website (labeled "hw") as canonical to other pages that are crucially important to our business. This blocks the important pages from being indexed in Google Search. In the screen shot, Google is selecting the hw page as canonical to an important page describing a software product named "DirectCore". As you can see from the hardware_products and DirectCore pages themselves, and the screenshots below, they are clearly and substantially different. A human would not label them as identical. Over the last few months I have followed Google's published instructions carefully, ensuring all of our pages use the https secure protocol, are mobile friendly, and describe unique content. For the hw page I tried a "noindex tag", submitting a request to Google's "URL Removal Tool" to de-index the page, and setting the page's priority to 0.1 in our sitemap. Nothing works -- Google for whatever reason is locked on to this page. I have sent countless feedbacks to Google on this issue. I have asked them for guidance and advice, as well as any possible workaround or fix that I can implement, and received no answer from them whatsoever. None of my efforts have had any effect, and the Canonical Page algorithm still inexplicably considers the hw page as a "phantom duplicate". The problem continues to occur with dozens of our company's website pages. What may be worse is that DirectCore is a registered trademark, and Google is unable to distinguish content even to the level of the US Patent and Trademark office. I can hardly find that believable, but evidently it is the case. I feel this is very unfair to small business; Google should work hard and pull their own weight like everyone else. If my company had a buggy algorithm in software we provide to customers we would be out of business. I am assuming this is a bug they can fix, or provide a workaround for, as I certainly hope Google's behavior is not something like Uber's "Greyball" that directly targets a subset of customers.
|
|
|
Forum / Thread Technical Discussions
SE Roundtable Thread, 26Dec18"Google is selecting an old, unrelated page as Canonical, blocking our pages from indexing", 15May19, Google WebMaster Forum
"Google selects one unrelated page as Canonical for many other pages, blocking our pages from indexing", 7Jun19, Webmasters Stack Exchange Thread
"Google selecting wrong canonical", 13Jun19, Google WebMaster Forum